Dijkstra算法的流程
以及到A*的优化和正确性问题的数学推导
最短路径:从Dijkstra到A-Star
Dijkstra 算法简介
Dijkstra 算法用于在一个图(Graph)中求“从起点到所有点的最短距离”,前提是边权重为非负。
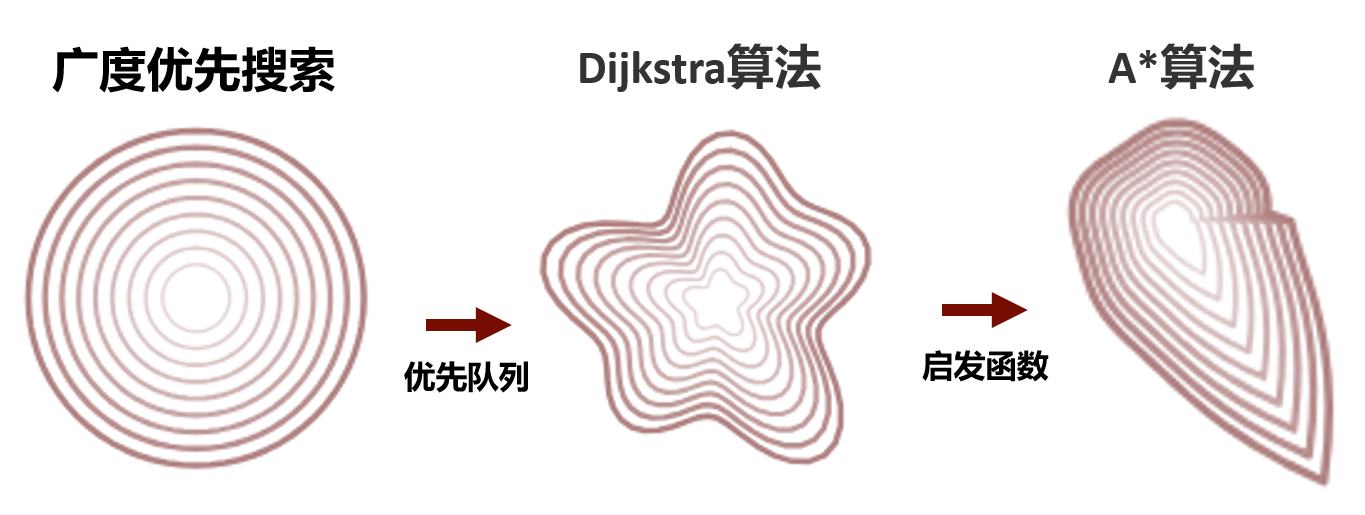
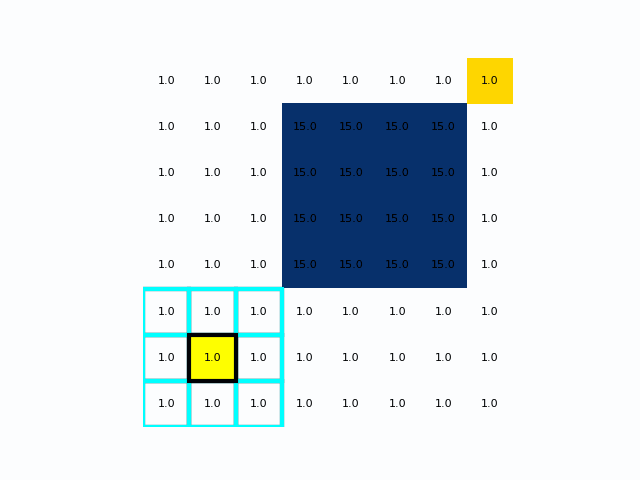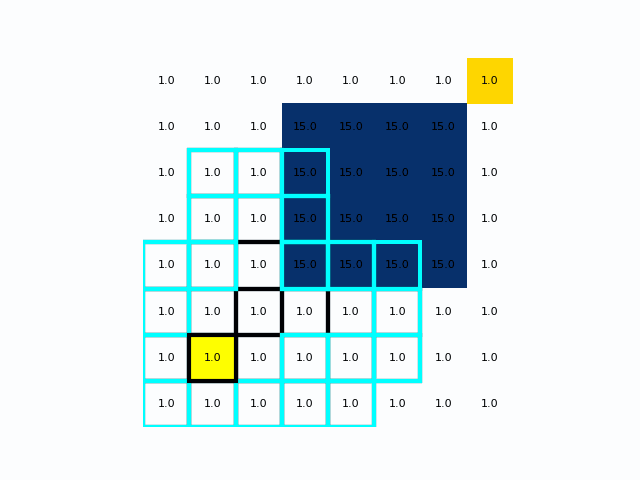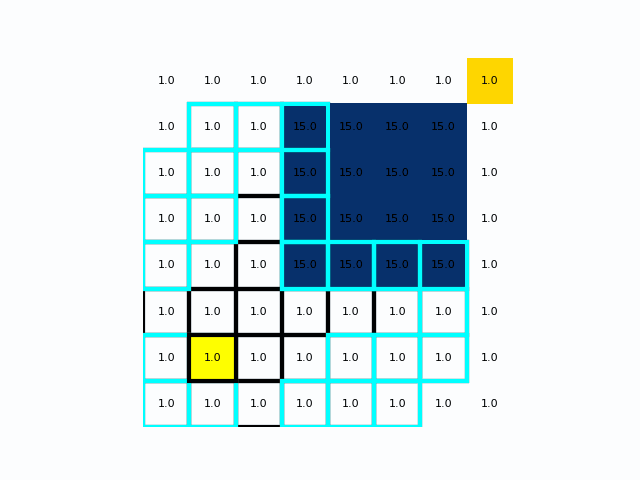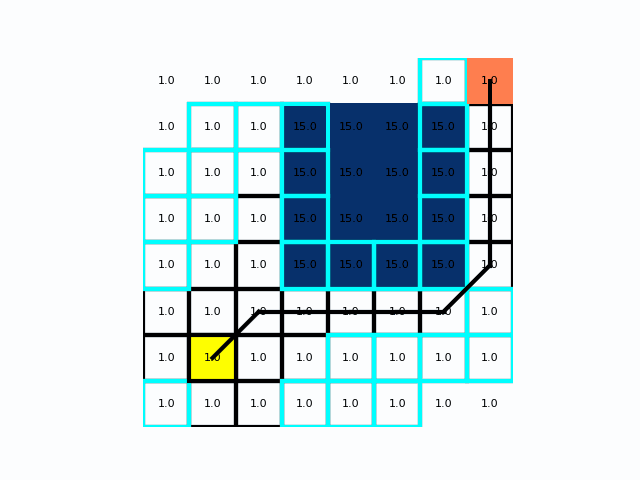
从左到右为BFS、Dijkstra、A*,在距离成本均匀分布时Dijkstra和BFS是一致的
核心思想是:每次从当前已知最短距离集合外选出距离起点最近的那个节点,把它的最短距离固定下来,然后更新它的邻接点。
- 维护一个
dist[u]:表示从起点到节点u的当前最短距离 - 维护一个优先队列(min-heap):按
dist取出当前距离最小的节点 - 更新近邻:对边
u -> v,- 若
dist[u] + w(u, v) < dist[v],则更新dist[v]并记录前驱(用于回溯路径)
- 若
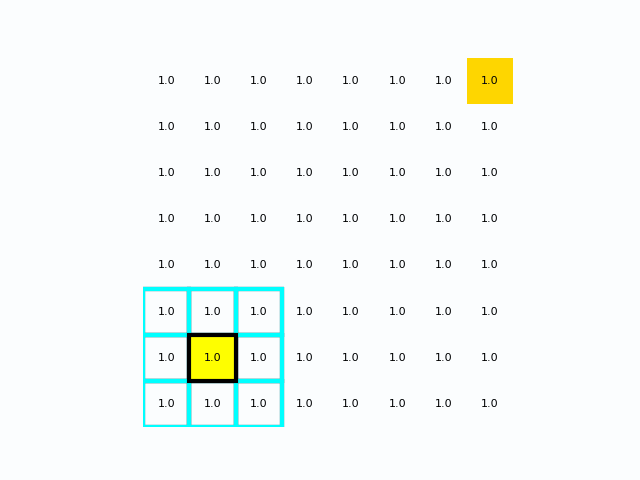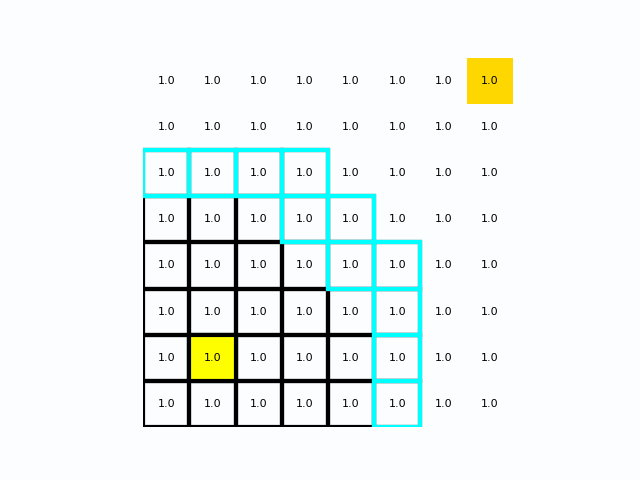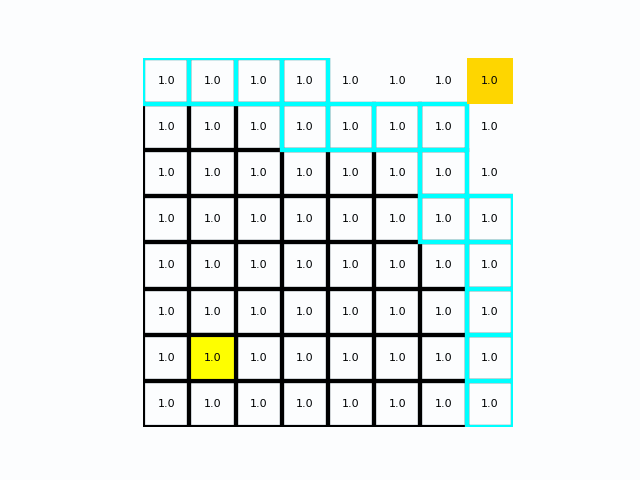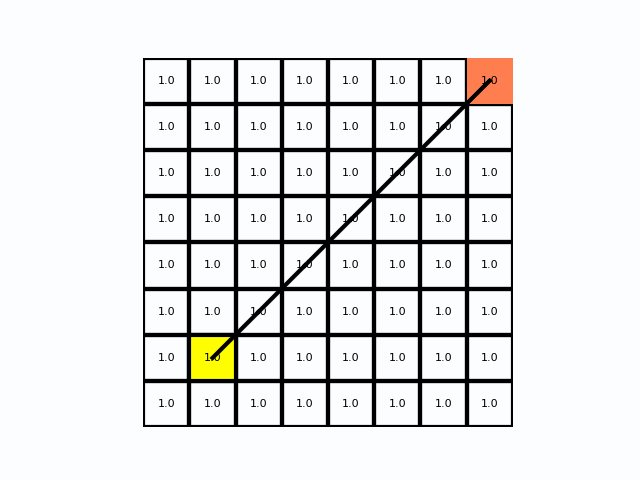
在距离成本均匀分布时Dijkstra
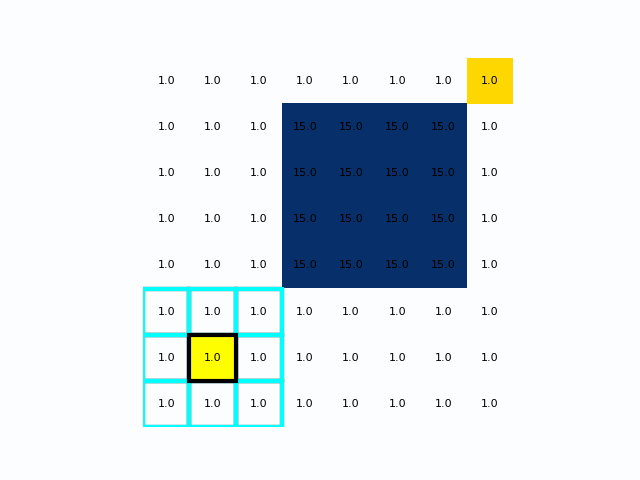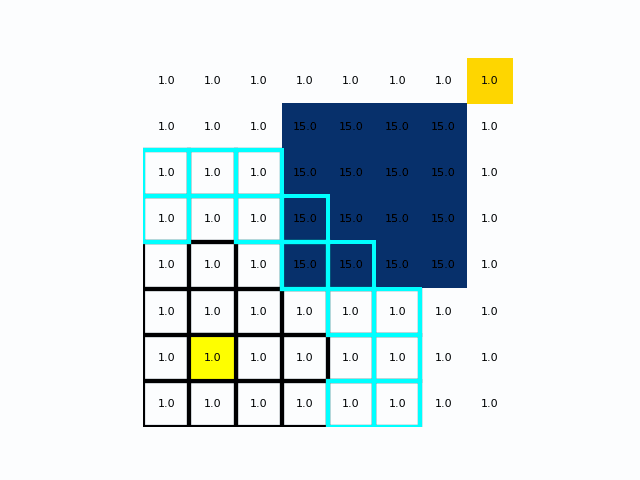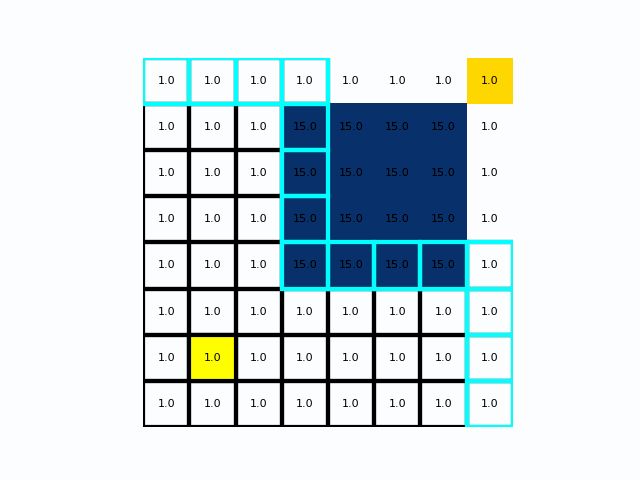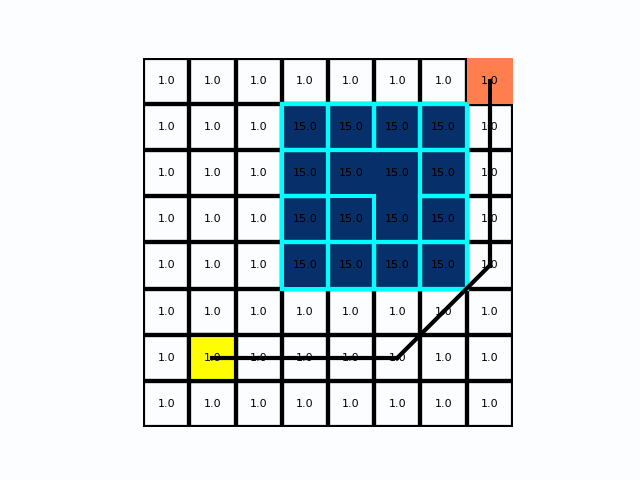
在距离成本不均时Dijkstra
在栅格/栅格图(例如把栅格像元当作节点)里,通常会把:
- 每个像元当作一个节点
- 相邻像元(4 邻域或 8 邻域)当作图的边
- 边权重由“从当前像元到邻居像元的移动成本”给出
Dijkstra 伪代码(用于把概念写成流程)
1 | Input: 图 G(V, E), 边权 w(u, v) >= 0, 起点 s, (可选终点 t) |
A* 算法简介(在 Dijkstra 上加启发式)
A*(A-star)仍然使用累计代价来保证最优性,但会引入启发式函数 h(n) 来“估计从节点 n 到终点还需要多少代价”,从而更快地把搜索聚焦到终点附近。
在 A* 中,优先队列一般按下面的评估函数排序:
f(n) = g(n) + h(n)
其中:
g(n):从起点到节点n的已累计成本(类似 Dijkstra 的dist)h(n):从n到终点的启发式估计成本
Astar算法
在栅格最短路场景中,常见的 h(n) 选择包括:
- 基于网格距离的估计(如曼哈顿距离用于 4 邻域,欧氏距离用于 8 邻域)
- 或者乘以一个最低可能移动成本的系数(让启发式更贴合成本栅格)
如何保证A*正确性(以及数学推导)
正确性要求:h(n) 不要高估真实最短剩余成本
设终点为 t,从节点 n 到终点的真实最短剩余代价为:
要求启发式满足(对所有节点 n):
接着给出常见的最优性推导思路(说明当启发式可采纳时,A* 弹出 t 时得到最短路径):
- 设存在一条最优路径 (P^{\ast}):
- 对路径上任意节点 (n_i),记从起点到 (n_i) 沿 (P^{\ast}) 的代价为 (g_i),从 (n_i) 到终点沿 (P^{\ast}) 的代价为 (r_i),显然:
- 由于 (P^{\ast}) 从 (n_i) 到 (t) 的这段路径只是一种“候选”,真实最短剩余代价满足:
因此可采纳启发式给出:
- A* 在搜索过程中维护的累计代价 (g(n_i)) 是“当前已知的起点到 (n_i) 最优近似”,一定满足:
于是可得该路径节点在 A* 的评估值:
也就是说:最优路径上的节点在 OPEN/候选集中始终存在某些 f <= C* 的节点,因此 A* 不可能“过早”弹出一个总代价大于
- 当终点
t被弹出时(通常满足),有:
由于上面的推理保证 f(t) <= C*,并且
因此 A* 返回的路径代价是最优的。